(Ancien calcul) Calcul de la prédiction de fraude
Le module Prochains passages repose sur une prédiction de la fraude à bord qui est réalisé en plusieurs étapes :
- Modélisation de la charge (comptages)
- Modélisation des montées/descentes
- Modélisation de la fraude
- Prédiction des courses
- Prédiction de la charge et de la fraude
Plus schématiquement, plusieurs modèles prédictifs sont générés à partir des données historiques, puis appliqués à des courses prévues.
La prédiction repose sur un certain nombre de concepts interdépendants :
Montées/descentes | Charge | |
Billettique (validations) | Montées/descentes (reconstitution billettique) - Montées = Validations (sauf validations qui n'ont pas pu être associées à une course et un arrêt) - Descentes reconstituées en même temps que la charge | Charge (reconstitution billettique) reconstituée à partir de l'algorithme Origine - Destination |
Cellules de comptage | Montées/descentes (cellules de comptages) données brutes | Charge (cellules de comptages) calculée à partir des Montées/descentes (cellules de comptage) |
Fraude (valeur absolue) | Montées frauduleuses/Descentes frauduleuses Montées/descentes (cellules de comptage) - Montées/descentes (reconstitution billettique) | Fraudeurs à bord (aussi appelée charge frauduleuse) Charge (cellules de comptage) - Charge (reconstitution billettique) peut aussi être calculée à partir des Montées/descentes frauduleuses |
Fraude (taux) | Taux de fraude à la montée/à la descente Montées frauduleuses/Descentes frauduleuses / Montées/descentes (cellules de comptages) | Taux de fraude à bord Fraudeurs à bord / Charge (cellules de comptage) |
1. Modélisation de la charge (comptages)
La prédiction de la charge commence par une étape de modélisation. Cette modélisation est basée sur un modèle simple : une moyenne du nombre de passagers à bord sur 6 mois glissants d'historiques de données de comptages.
Un certain nombre de filtres est appliqué sur l'historique de données avant modélisation.
Les moyennes sont calculées :
- par jour de la semaine
- par quart d'heure
- par ligne, direction et chaînage
- par station
Par exemple, on calcule la charge moyenne le mardi sur la ligne 1 dans la direction 2 à la station Gare SNCF entre 14h15 et 14h30 sur la base de toutes les courses enregistrées sur ce périmètre sur les 6 mois glissants.
Dans une future version, la modélisation se fera à l'échelle de la course (charge à bord pour chaque arrêt sur la course de 9h06 ou 9h14 et non sur les courses entre 9h et 9h15).
Elle prendra également en compte les niveaux de fréquentation (périodes scolaires vs vacances).
Si aucune course n'a été enregistrée sur un périmètre spécifique au cours des 6 derniers mois, il n'y aura pas de prédiction possible. Il n'y aura pas non plus de prédiction si moins de 10 000 courses sont disponibles dans l'historique de données sur le chaînage concerné.
2. Modélisation des montées/descentes
Les modèles de prédiction de charge et de fraude ne sont pas calculés sur les mêmes échelles :
- la charge est modélisée à bord du véhicule, entre deux stations ;
- la fraude est modélisée à la montée et à la descente, à une station donnée.

Pour pouvoir combiner les deux modèles, on utilise un troisième modèle qui va permettre de convertir un nombre de passagers en un nombre de montées/descentes.
Le principe de ce troisième modèle est de déterminer un ratio montées/descentes, qu'on pourra appliquer à l'écart de charge avant et après échange voyageur à une station donnée.
Ce modèle est calculé sur les mêmes données que le modèle de charge, après les mêmes filtres, avec les paramètres suivants :
- ligne et direction
- station
La version actuelle de ce modèle ne prend pas en compte le jour de la semaine et l'heure de la journée. Cette prise en compte fait partie des évolutions prévues.
Par exemple, si en moyenne, à la station Gare SNCF, j'ai
- 20 passagers avant échange voyageur
- 24 passagers après échange voyageur
- un ratio montées/descentes de 2
j'aurai
nb descentes - nb montées + 20 = 24
⇔ nb descentes - 2 (nb descentes) + 20 = 24
⇔ nb descentes = 4
soient 4 descentes et 8 montées.
3. Modélisation de la fraude
La prédiction de la fraude commence elle aussi par une étape de modélisation. Cette modélisation est basée sur un modèle d'apprentissage machine (random forests).
Un certain nombre de filtres est appliqué sur l'historique de données avant modélisation.
La valeur modélisée est le taux de fraude à la montée (équivalent à l'agrégation "taux" de l'indicateur "Montées frauduleuses"). On s'appuie ainsi sur les mesures les plus directes dont on dispose (par opposition à la charge ou aux descentes qui sont reconstituées algorithmiquement) :
- nombre de validations
- nombre de montées (cellules de comptages)
La formule est
(nombre de montées (cellules de comptage) - nombre de validations) / nombre de montées (cellules de comptage)
Le modèle prend en compte les paramètres suivants :
- jour de la semaine
- quart d'heure
- ligne
- station
Le principe de ce modèle est de pouvoir estimer la fraude finement, par exemple à la station Gare SNCF sur la ligne 1 entre 10h et 10h15, par rapport à une autre station ou dans le quart d'heure suivant.
4. Prédiction des courses
en cours
5. Prédiction de la charge et de la fraude
Une fois les courses prédites, les modèles successifs sont appliqués pour calculer une charge et une fraude à bord.
- Prédiction de la charge par station sur chaque course (modèle 1.)
- Conversion de la charge en montées/descentes (modèle 3.)
- Application du taux de fraude prédit aux montées/descentes (modèle 2.) pour déterminer un taux de fraude à la montée et à la descente
- Conversion du taux de fraude à la montée et à la descente en nombre de montées/descentes frauduleuses (montées x taux)
- Conversion du nombre de montées/descentes frauduleuses en fraudeurs estimés
Les courses prédites avec charge et fraude à bord sont ensuite exposées sous forme d'API pour le module Prochains passages.
6. Evaluation de la prédiction
La précision de la prédiction peut être évaluée sur demande, sur un réseau spécifique. On évalue cette prédiction en analysant a posteriori l'écart entre les données historiques et les valeurs prédites.
A titre d'illustration, quelques métriques :
Prédiction de la charge
- En valeur absolue, entre 0 et 5 passagers d'écart par rapport aux données historiques (peut aller jusqu'à 10 pour une ligne de tram)
- En taux de charge, 1-2% d'erreur par rapport aux données historiques
Des phénomènes précis et localisés, comme une course très chargée vers un centre logistique en début de service, peuvent faire monter l'écart entre le taux de charge prédit et le taux de charge observé à plus de 20% sur une tranche horaire de 15 minutes.
Prédiction de la fraude
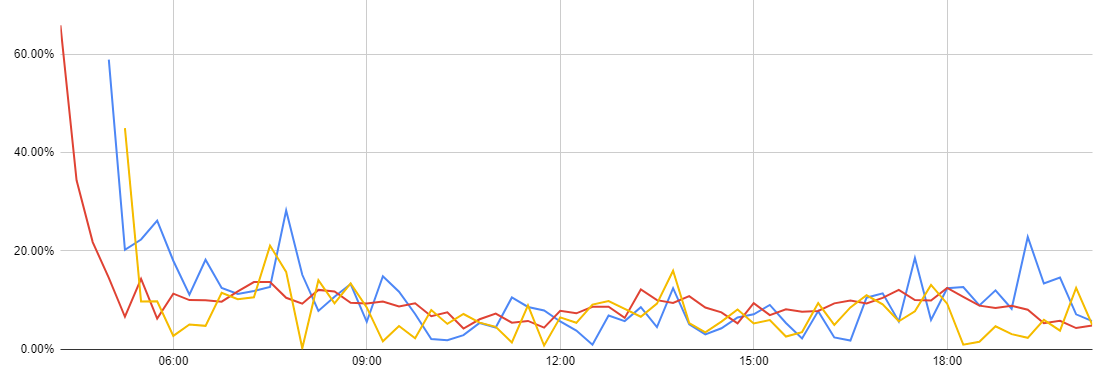
L'écart entre le taux de fraude mesuré et le taux de fraude prédit est en moyenne de 10%.
Il est très important en tout début de service.
Cette moyenne de 10% d'écart veut dire que si on prédit qu'il y aura 10 fraudeurs à bord d'un véhicule, il peut en réalité y en avoir entre 9 et 11.
Le graphique ci-dessous montre la variation de cet écart au cours de la journée, sur trois réseaux tests :